
End-to-end contracts using protocol buffers
Endika Gutiérrez
Software Engineer
Even in small teams, working on modern applications implies to define and fulfill contracts and unify the language different teams or departments talk. At Líbere we’ve tried to bring this idea to all facets of our technological stack. In this post we will try to explain how we have managed to carry out this idea relying on protobuf definitions as a single source of truth (SSOT) for any entity in our business.
Currently we have over 30 services covering many areas of the hospitality business, such as housekeeping, billing or smart locks accesses. As we were growing, a more scalable approach was required to define tons of different business models.
TL;DR We decided to move to protobuf as the language for defining domain models and services, and gRPC as synchronous Remote Procedure Call (RPC) framework.
Protocol buffers, also known as protobuf, is an open source platform developed by Google that defines a way to serialize data based on an interface definition language that describes its structure.
Using protocol buffers, we are able to generate code for any language, but not only that, we also relay on protos for:
- Events definition for asynchronous communication.
- Data warehouse schemas definition.
- Front-end and internal tools REST APIs.
- Mailing templates input data.
- APIs documentation.
Why to care about RPC technology?
As usual, we relied on the REST pattern for inter-services communication. That
implied to deal with manually crafted Go modules that were shared across
different projects.
Same problem was faced when using google PubSub for async communications,
where we had to copy-paste DTO definition accross publishers and consumers.
That made it hard to enforce rules, which tend to be interpreted as guidelines, and we ended up spending too much time trying to keep uniformity/consistency, and writing boilerplate code.
Furthermore, we ended up building some tooling around existing technologies, instead of addressing the root cause.
And… Why gRPC?
There are many awesome RPC technologies, but choosing one, to a greater or lesser extent, compromises the development process, and changing it later is something relatively complex.
gRPC is a high performance RPC framework, also developed by Google, built on top of protocol buffers that allow to define service interfaces using the same protobuffs and generates clients for any supported language.
That said, gRPC is a widely used language agnostic technology that has a vast ecosystem surrounding it. It is easy to extend and adapt to different needs.
What does it look like?
Among the different options, a single protos definition repository was the best suitable approach for us. Comparing with the obvious alternative of defining APIs per service or team, a SSOT for any piece of data that travels around our infrastructure offered us certain advantages:
- Having a more complex (or advanced) CI pipeline without extra maintenance
work in multiple repositories. In fact, we generate
clients and services code, mocks, REST gateways, OpenAPI
documentation and breaking checks. Is that all? nope! We
automatically create or update data warehouse tables on each release of
libereapis, and Pub/Sub topic schemas are uptaded too. - We define APIs that act as composition of multiple domains. That's, for example, the role of gateways in our infrastructure.
- Some basic types and metadata is shared across different domains, so no external modules are required avoiding complex dependencies.
For the protos lifecycle we use the awesome, highly-customizable and extremely fast buf tool. It integrates seamlessly with existing protoc plugins like the protoc-gen-bq-schema, which we use for the schema generation.
Pub/Sub topics and schemas are enforced based on the definition contained in
the protos, and Dataflow job is
responsible for dumping the data from those Pub/Sub topics to the data
warehouse and to the datalake.

Thereby, any change on models is transparently reflected in the whole data pipeline, keeping consistency across the whole system.
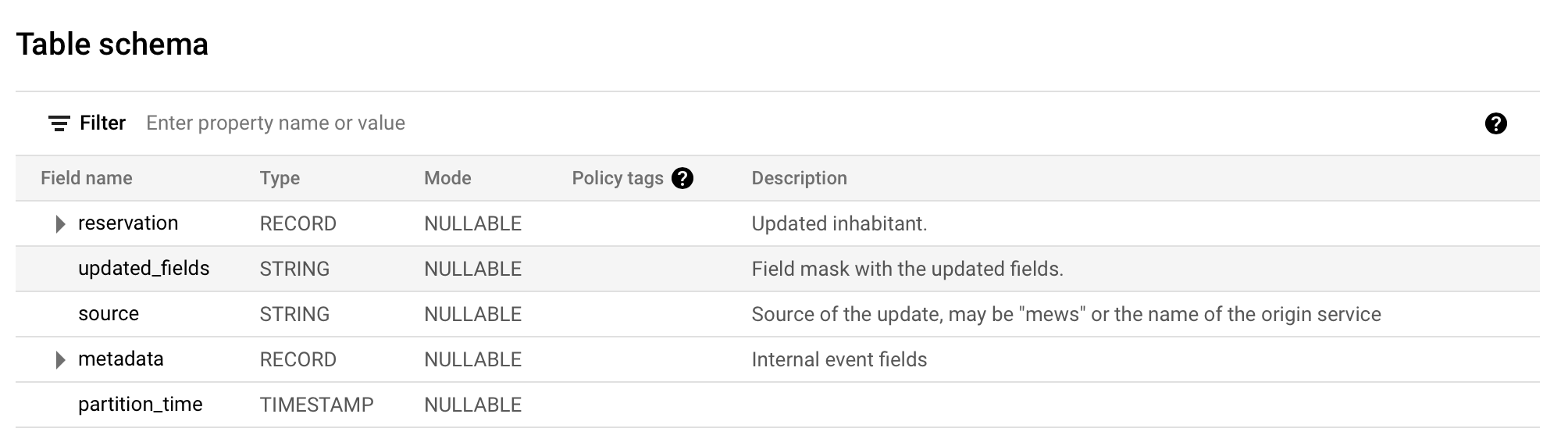
Let's asume that we have an update event for the Reservation entity:
// An event that represents an update of reservation
message ReservationUpdatedEvent {
option (gen_bq_schema.bigquery_opts).table_name = "reservation_v1_ReservationUpdatedEvent";
option (eventbus.v1.event_opts).topic_name = "domain.reservation.v1.reservation-updated";
// Updated reservation, contains the final state of the entity.
Reservation reservation = 1;
// Field mask with the updated fields.
google.protobuf.FieldMask updated_fields = 2 [
(gen_bq_schema.bigquery) = {type_override: 'STRING'}
];
// Update source.
string source = 3;
// Internal event fields
eventbus.v1.Metadata metadata = 2046;
google.protobuf.Timestamp partition_time = 2047;
}
Once this event is published, it will be automatically stored in BigQuery:
What's next?
As complexity of models grows, there is an impact on the maintainability of our frontends and gateways, which aggregate multiple domains responses. At the engineering team, we have begun to consider the possibility of using GraphQL as query language for the public APIs.
GraphQL is a query language for APIs that allows clients to define the structure of data requested. Similarly to protocol buffers, an interface definition language is used to represent the different entities and their relationship, and through its query language, clients are able to traverse different entities like a graph retrieving all data in a single request.
As an example, suppose the following request:
{
reservation(confirmationNumber: 'LVGA987') {
checkinTime
inhabitants {
name
}
space {
name
status
category {
name
}
}
}
}
Here we are composing a request that involves different systems, reservations, inhabitants, spaces and housekeeping. Now, think on these entities as views of our internal entities defined as protos.
This is the first post of the serie, stay tuned!
Ah! did we mention that we are hiring Software Engineers? Come and join us!