
It is never too early to start with data governance
Jose Gargallo
CTO
In this very first post we want to share an initiative to push one of our core values: taking insights-driven decisions. Piling up data is not enough; you need to make sure your data can transition to insights, and one process that helps to meet this goal is data governance (DG).
It's been a year since I contacted some former co-workers from the data industry to ask for advice about building a very light data governance framework. The first reaction was reassuring: "A CTO thinking on Data Governance on the early days! this is the dream scenario. It is never too early to start with data governance".
Initially, you might think this is too much for an early-stage startup, and that's why is so important to build a light framework adapted to the reality of your company. So what were we concerned about?
- Silos. We wanted to break down data silos in the organization. We aim for centralized coordination, and data standards allow for better cross-functional decision-making and communication. I'm sure you've been in a meeting where different departments show different numbers for the same metric ;) Let's agree on what the data at our disposal means!
- Looking at the wrong data. We need to ensure data quality across the whole organization to make business decisions based on the most accurate data possible.
- Regulatory compliance. What about PCI or GDPR? Stable data makes adapting to new data and privacy legislation easier. This is super important for international companies exposed to different regulations.
- Data democratization. Data must be accessible by the whole organization.
- Data swamp. Yep, we've seen that many times in the past, so we better keep data growth under control and organized from day one. Let's keep dreaming about swimming in a pristine data lake!
Cool, so how do we put this into practice? Show me the framework!
The framework
Documentation about data governance is pretty extensive, but we wanted to start by defining a pretty light process and the roles involved in it.
About the roles, we started by defining three:
- CDO (chief data officer), the one leading the program. I looked around, ok, we are a small cross-functional team, I will play this role.
- DG committee, which approves the foundational data governance policy. Ok, let's share this responsibility between Santi (CPO) and myself.
- Data stewards. Ensure data quality, privacy, and security. No problem, the whole product team will pay special attention to data.
We wanted to make the process very simple, and since we already had a product framework, small changes were applied to adapt it for data products. These are the steps for each project/initiative:
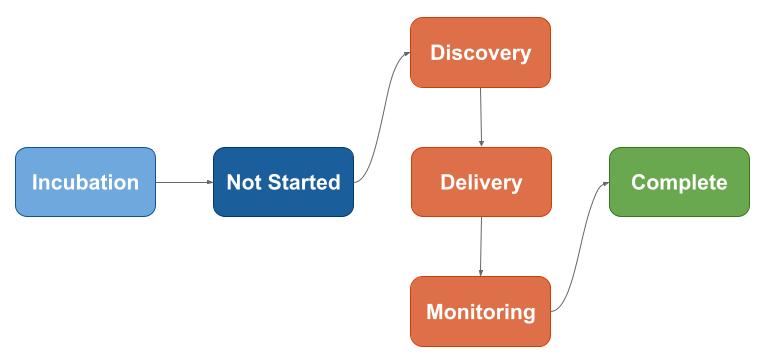
And a few steps were adapted:
Discovery
A policy compliance section was added and validated by the DG committee (a.k.a CPO + CTO). It looks very corp, but it's just a checklist around data integrity, accessibility, usability, privacy, and security:
Integrity
Focusing on quality checks, lineage and transformation monitoring, we started by documenting our domain events. This sounds weird, but due to the nature of our data sources, which most of them are external to our systems, we started with an event-driven architecture, hence the need to document these first transformations.
Here is an example about naming conventions:
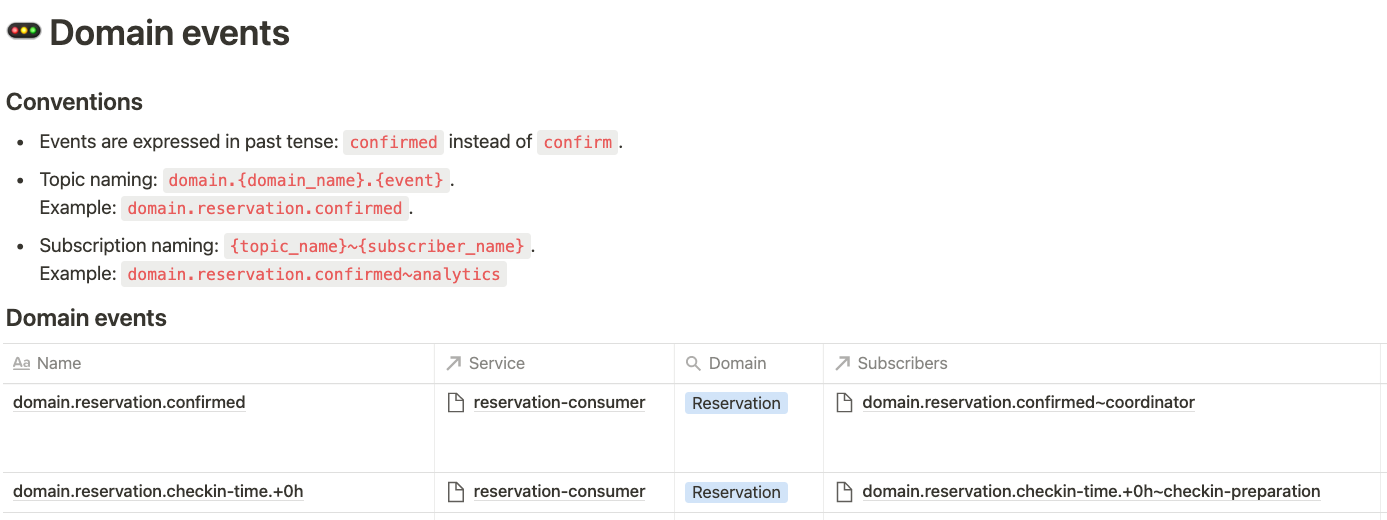
From these events, we apply the first data transformations to adapt it to our models, which are represented in our data catalog in the form of data sources, fact tables, and dimension tables.
Fact table examples:
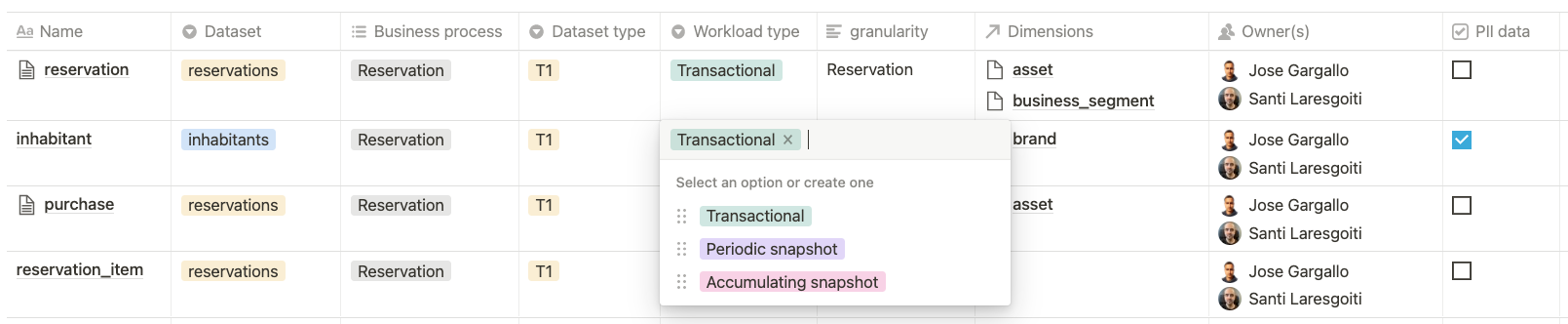
Dataset type indicates the number of data transformations from origin: application, raw data / T0, T1 or T2 (representing multiple transformations).
Accessibility
We wanted to answer: how to access data, how fresh, is it enough?
We decided to use Metabase, an open-source tool that helps us to ask questions and learn from data easily. It is well integrated with Big Query, one of the main pieces inside our data lake.
The whole company has access to Metabase, but the DG framework applies only to some collections such as company KPIs.
About data freshness, most of our data come in real-time. This looks ideal, but we know we took many shortcuts to build a short-term solution that will work as long as the data volume ingested remains manageable. Huge room for improvement ahead, but we were new on the business, so making data accessible to the whole org was a priority over building a long-term data engineering platform.
Usability
Making data usable across the whole org is a challenge, we know it easily goes out of control, so besides documenting schemas and ways to join and enrich our data, we have created a BigQuery dataset accessible from Metabase where only views representing our models are exposed. It is the simplest way to abstract our data pipelines which will continuously change over time.
PII (Personally Identifiable Information) data
We wanted to avoid storing PII data unless strictly necessary, and in that case, we wanted to label datasets accordingly on our data catalog.
Security
As a starting point, we have delegated most of our security to GCP managed services and an OAuth proxy. A lot of work remaining in terms of authorization based on roles.
Delivery and monitoring
As part of delivery, we update our data catalog: data sources, data transformations, fact tables and dimension tables.
During monitoring, DG committee will be involved to validate data policy compliance, which means we validate what was defined during discovery.
A success story
Companies need to demonstrate how effectively are achieving their key business objectives, and this is usually done by defining KPIs. Some of them, such as ADR (average daily rate) or occupancy, are high-level and focused on the overall performance of the business, but others, such as DRR (direct revenue ratio), are lower-level and focused on processes in specific departments.
We decided that KPIs' definitions, no matter the level, must go through the DG framework, and this helped us to successfully align all departments on what each KPI means, define the calculation criteria, what's the desired outcome, how progress is measured, and who is responsible for the business outcomes.
We've been able to define a ubiquitous language for terms like habitable unit. It represents beds for hostels, rooms for hotels, and apartments for aparthotels and apartments. By defining this term, we can talk about global occupancy where depending on the context everybody knows what occupancy means.
That's it, hopefully, this post will inspire you to start thinking about data governance from the very beginning of your next gig ;)
Ah! did I mention that we are hiring our first Data Scientist? Come and join us!